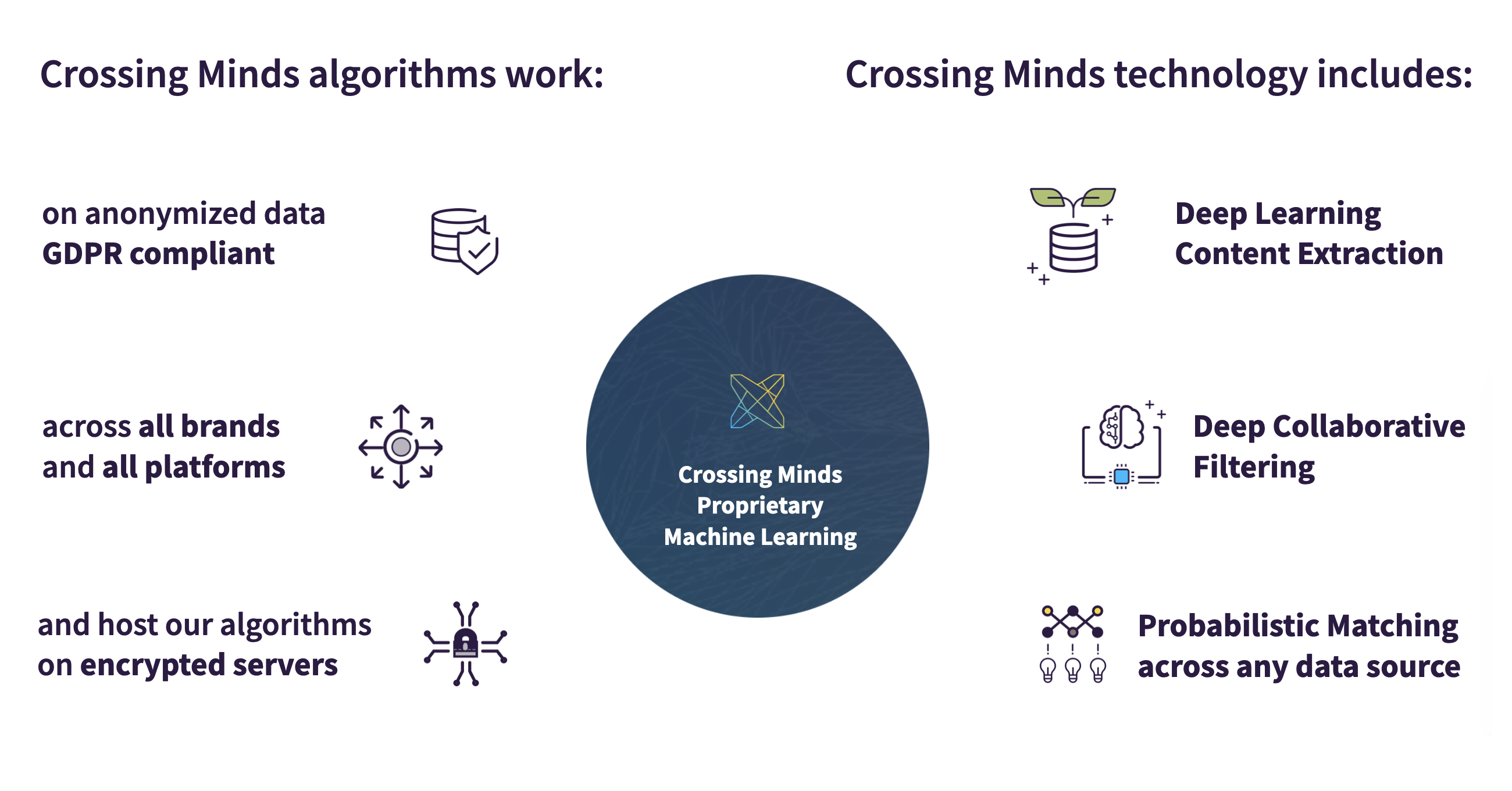
Deploying complex infrastructure with heterogeneous data raises significant technical problems. From storage to real-time processing and batch analysis, all the steps of a data pipeline are made tedious when dealing with sparse and weakly structured data sets. The ideal solution to address this problem is condensing all the available data into compact, meaningful representations: embeddings.
An embedding is a low-dimensional vector of continuous numbers learned to store the relevant information in a compact and convenient form. Embeddings are designed to reduce the dimensionality of both categorical and continuous features.
The expressive power and convenience of embeddings is witnessed by their rising role in the state-of-the-art of the machine learning literature.